VF3剪枝调研
0. 前言
定义
- g1为小图,模式图
- g2为大图
伪代码


1. 点的优先级
这里的点的优先级指的是遍历枚举中g1的点的优先级,优先考虑约束多的点,
- 在大图g2中找到对应节点的可能性比较小的优先。
- 和已经匹配上的节点连接比较多的应该优先。
通过这样判断枚举的点的优先级可以尽快的剪掉不可能的分支。
1.1 点的匹配概率
定义pf(u)为在g2中找到一个节点v可以和g1中节点u匹配上的概率。
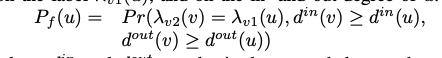
其中
- λu1(u)指u在g1中的标签,λv2(v)指v在g2中的标签
- din是入度
- dout是出度
v和u匹配,必须满足3个条件
- 两个节点的label相同
- g2中节点的v的入度不小于g1中节点u的入度
- g2中节点的v的出度不小于g1中节点u的出度
pf(u)就是同时满足这3个条件的概率,计算这个概率的时间复杂度最差为On3,于是看成3个独立的条件概率,公式可以变为

其中pl(l)是节点v的label是l的概率,这个计算的复杂度下降为On。
1.2 点的匹配顺序
定义g1中点的顺序为ng1,定义dm为一个节点与已经加入ng1里的节点相连的数量。
排序规则:
- dm大的优先级高
- dm相等的情况下按pf排序,pf小的优先级高
- dm和pf都相等的情况下,考虑节点的度,度大的节点优先级高
- 如果三者都相等,则顺序任意
按上述排序规则取出优先级最高的点加入ng1,不断的重复上述过程知道所有的点都已经加入ng1。
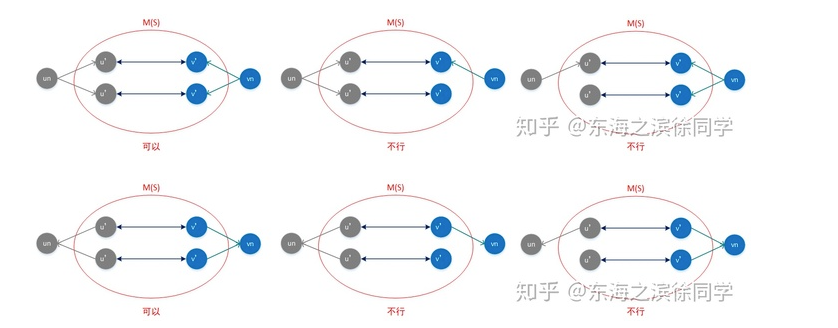
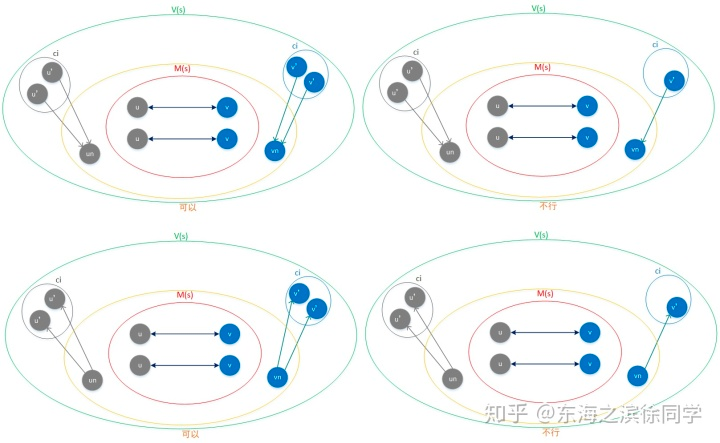
2. 状态可行性判断
定义Sc 为一个符合匹配的一致状态,判断要新加入的的候选节点对(un,vn)是否可行,需要保证这个节点对加入Sc后,Sc依赖是符合匹配的。
un 是 g1(小图)中的节点,vn是g2(大图)中的节点
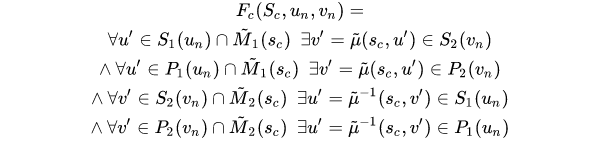
- S1(un)是un节点的所有后续节点构成的集合,P1(un)是un节点的所有前驱节点构成的集合,S2(vn),P2(vn)同理。
- M1(Sc)表示Sc中属于g1图的节点集合,M2(Sc)表示Sc中属于g2图的节点。
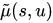 表示M(s)中与u对应的点。
表示M(s)中与u对应的点。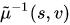 表示M(s)中与v对应的点。
表示M(s)中与v对应的点。
通俗的说就是un与已经匹配上的M1(Sc)中的关系和vn与已经匹配上的M2(Sc)中的关系要一模一样的,un有的,vn也要有,不能多也不能少,方向也要一致。
3. 未来状态判断
3.1 1-lookahead
3.1.1 定义
V1代表g1图中的点集合
E1代码g1图中边的集合
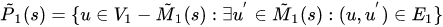
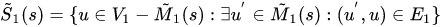
~P1(s) 表示 g1中去除已经在匹配状态的点 剩下的与匹配状态中的点是前驱节点的集合
- ~S1(s) 表示 g1中去除已经在匹配状态的点 剩下的与匹配状态中的点是后续节点的集合
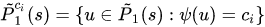 表示~P1(S)中属于种类i的节点的集合。
表示~P1(S)中属于种类i的节点的集合。- 下标为2的时候代表g2图。
3.1.2 判断公式
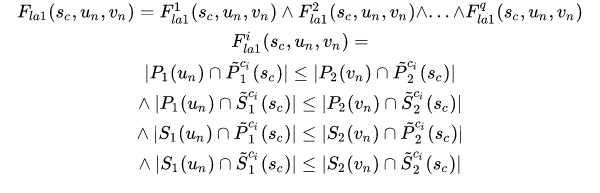
对任意种类的点,g1(小图)中的点的数量都不能大于g2(大图)中的点的数量,否则未来就必然会匹配不上。
3.2 2-lookahead
更进一步考虑未来的情况
3.2.1 定义
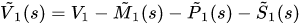
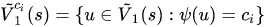 代表在~V1(s)中属于i种类的点的集合
代表在~V1(s)中属于i种类的点的集合- 下标为1代表g1,下标为2代表g2
3.2.2 公式
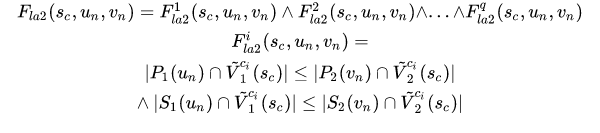
需要满足小图中符合条件的点的集合大小不大于大图中符合条件的点集合大小。
4. 参考
https://blog.csdn.net/weixin_33187773/article/details/113055063